英伟达「五层蛋糕」架构拆解:AI基建新浪潮的底层逻辑与产业机遇
2017年,当我第一次在行业峰会上听到黄仁勋提起「算力即国力」这个论断时,台下响起的掌声稀稀拉拉。彼时GPU还在游戏和图形渲染领域打转,没有多少人体会到这句话的真正含义。九年后,这位英伟达掌舵者在署名长文中抛出重磅观点:史上最大规模的AI基础设施建设才刚刚开始。
回溯算力进化的时间线
让我们把时钟拨回到2012年。那一年的ImageNet挑战赛,AlexNet用GPU撕开了传统计算机视觉的防线,算力利用率从可怜的20%直接跳到80%。这不只是算法的胜利,而是底层硬件逻辑被彻底重写的信号弹。GPU的并行计算架构天然适配深度学习,NVIDIA从那一刻起就不再是显卡公司。
2017年Transformer架构登场,参数规模从百万级冲向亿级。BERT、GPT系列模型参数量爆炸的背后,是英伟达芯片从P100→V100→A100→H100的四年三连跳。这条进化链路的本质是什么?单位算力成本每年下降40%,但模型能力每年提升10倍。
五层蛋糕:从能源到应用的价值链条
黄仁勋在文中重新定义的「五层蛋糕」架构,本质上是一份AI时代的基建路线图。
最底层是能源层。这不是传统的电网概念,而是支撑实时智能生成的电力基础设施。马斯克押注的千亿美元储能计划、本次GTC大会上披露的液冷数据中心布局,都在指向同一个事实:算力的天花板不再是芯片制程,而是供电能力。
第二层是芯片层。Blackwell架构的晶体管密度已经逼近物理极限,但黄仁勋在署名文章中强调的关键词是「效率」。能效比每提升1%,同等电力就能多跑2%的推理任务。这解释了为什么英伟达一边卖芯片,一边重金投入能效优化。
第三层是基础设施层。这包括土地、供电、冷却系统、建筑工程、网络通信和系统集成。过去一年全球新建的AI工厂数量,超过了此前十年的总和。超大规模数据中心正在从「存放服务器的建筑」进化为「智能生产工厂」。
第四层是模型层。DeepSeek-R1的开源策略是这一层最值得关注的变量。当免费模型达到前沿水平,整个技术栈的需求被重新激活。这不是零和博弈,而是生态扩容。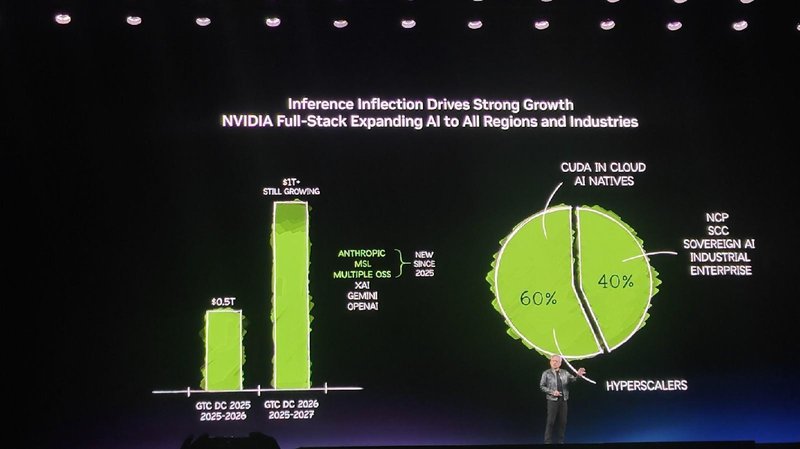
最顶层是应用层。经济价值在这里兑现,但每1美元的应用收入,都会沿着层级向下传导,激活能源、芯片、基础设施的持续投入。
方法提炼:看懂这一轮AI基建的方法论
如何判断一个AI基建项目是否值得投入?这里给出三个核心指标。
第一,能源转化效率。数据中心每消耗1度电,最终产出多少有效算力。这不是实验室数据,而是实际运行负载下的PUE值。优秀项目的PUE已经压到1.1以下,顶尖项目能做到1.05。
第二,模型适配深度。基础设施能否高效承载多种架构的模型推理?支持TensorRT、ONNX、PyTorch等多种框架的部署能力,决定了基建的灵活性和利用率。
第三,扩展弹性系数。从单机柜到集群,数据中心能否实现线性扩展?延迟抖动控制在5%以内的能力,是工业化AI生产的基本门槛。
应用指导:三个赛道的入场时机
基于上述分析,以下三个赛道目前处于最佳入场窗口期。
首先是液冷散热系统。单芯片TDP突破1000W的时代,传统的风冷方案已经触及物理瓶颈。浸没式液冷和冷板液冷技术正在从实验室走向商业部署,这个赛道的技术门槛和客户粘性都很高。
其次是网络通信设备。AI工厂内部的数据交换量已经超过大多数城域网,单个训练任务需要协调数万台GPU。没有专线级的RDMA网络,整个系统的训练效率会下降60%以上。
最后是高密度电源模块。48V直流供电架构正在成为超大规模数据中心的标配,围绕这个标准的电力电子改造需求,催生了一个百亿美元级的新市场。


